最終更新日 2011.12.22
鍋田形式バイナリへの変換登録画面へ(各種テキストファイル、CGIデータ)
鍋田CGIデータ直接検索設定画面へ(CGIデータ)
テキストファイル直接検索設定画面へ(各種テキストファイル)
EPWING設定画面へ
PDICデータ直接検索設定画面へ(拡張子*.DICのPDICデータ)
鍋田CGIデータ作成
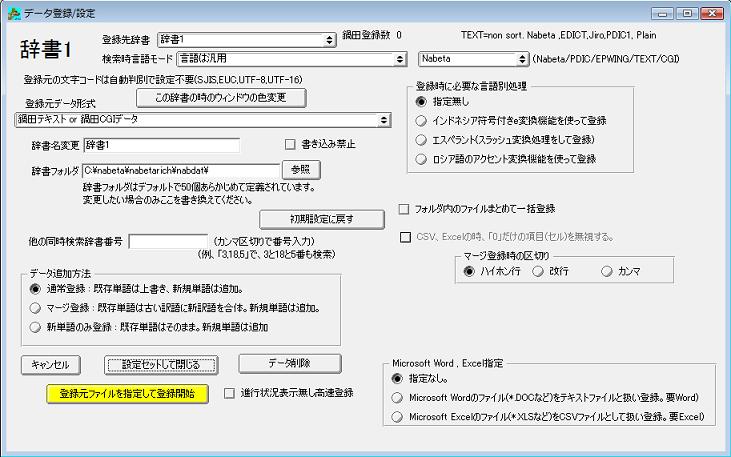
鍋田形式バイナリに変換可能なデータは、鍋田テキスト、鍋田CGIデータ、CSVファイル、EDICTテキスト(EDICT2、CEDICT、Wadoku含む。EDICT2はVer 4.8以降)、辞郎テキスト(Ver 4.8以降)、エスペラントPEJVO.TXT形式テキスト、Wx2+テキストPDIC1行テキスト、PDICテキスト、ロワイヤル仏和中辞典第二版CD-ROMです。
テキストファイルの場合は、文字コードはSJIS、EUC-JP、UTF-8、UCS2を自動認識して変換取り込みします。
EUC-JPは旧バージョンにバグがあるためVer 4.8以降で登録してください。
EUC-JPテキストの読み込みはVer 4.8でJIS X 0212拡張(補助漢字など)に対応しました。
EUC-JPテキストの書き込みはVer 5.0でJIS X 0212拡張(補助漢字など)に対応しました。
(EDICT2の配布テキストがEUC-JP JIS X 0212拡張だったため)
テキストファイルまたはCGIデータなどから鍋田形式に登録する場合の登録先データフォルダはあらかじめ定義されています。
変換先のデータフォルダを変更したい場合は、辞書フォルダを入力します。
登録したい辞書番号、登録元データ形式などを選びます。
すでに登録している鍋田形式データがある場合、追加される形になります
完全に上書きしたい場合は、一度「データ削除」ボタンをクリックしてパスワードの「sakujo」を入力して削除してください。
すでに登録しているデータがある場合、「通常登録」と「マージ登録」を選ぶことができます。
「通常登録」を選ぶと同じ単語は上書きされ、旧データに無い単語は新規登録されます。新データに無い旧単語はそのまま残ります。
「マージ登録」を同じ単語があった場合、上書きされずに旧データの次に新データが追加されます。。
マージ登録をする場合の旧データと新データの区切りは「ハイホン行、改行、カンマ」から選べます。
各選択をしたあと、最後に「登録元ファイルを指定して登録開始」ボタンを押して登録元ファイルを選ぶと登録が始まります。
データ量によっては登録に時間がかかることがあります。
鍋田形式のデータ登録は基本的に追加のみです。
完全な上書きは「データ削除」を行ってから登録することでできます。
追加なので、十万件データが登録してあるところに5件のデータを追加登録する場合も、5件しか登録しません。
追加という概念がなければ十万五件もういちど全部登録しなおさなければならなくなりますが、鍋田辞書には追加という概念があるためにそのような無駄がありません。
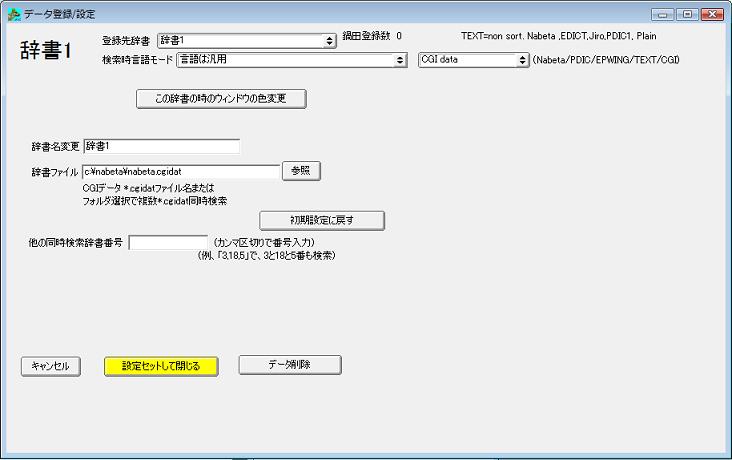
Ver 4.2からCGIデータという新形式に対応しています。(CGIという名前が付いていてもWindows版で検索できます。)
CGIデータはWindows版とPerl版とPHP版の鍋田辞書の共通データ形式であり、WEBブラウザ(IEやfirefoxなど)から検索させることも可能なデータ形式です。
変換データを作成せずに直接、拡張子 *.cgidatのCGIデータを検索するには右上の「Nabeta/PDIC/EPWING/TEXT/CGI」で「CGI」を選んでください。
「辞書ファイル」を入力して「設定セットして閉じる」ボタンを押すと完了です。
フォルダを指定した場合は、フォルダ内の拡張子*.cgidatのファイルを全て同時検索します。
拡張子*.cgidatのファイル名を指定した場合はそのファイルのみ検索します。
CGIデータ形式以外との辞書と同時検索する場合は、「他の同時検索辞書番号」の入力欄に他の辞書番号を半角でカンマ区切りで書き「辞書グループ(串刺し)(他の同時検索辞書)セット」ボタンをクリックします。 。
例えば、「3,18,5」の入力で3と18と5の辞書番号の辞書を順に検索します。
CGIデータ設定画面では「登録元ファイルを指定して登録開始」ボタンは消えます。これはクリックする必要はありません。
CGIデータの直接検索は、登録変換時間がかからない、データサイズが小さい、複数辞書の同時検索が簡単、ひとつの辞書のファイルがひとつで管理しやすいなどの利点があります。
欠点は、読み込み専用でありWindows版でそのまま検索させる場合はデータ編集や、単語の追加ができないことです。(現在のバージョンでは)
データ編集や、単語の追加をしたい場合は、。鍋田形式に変換することで可能です。
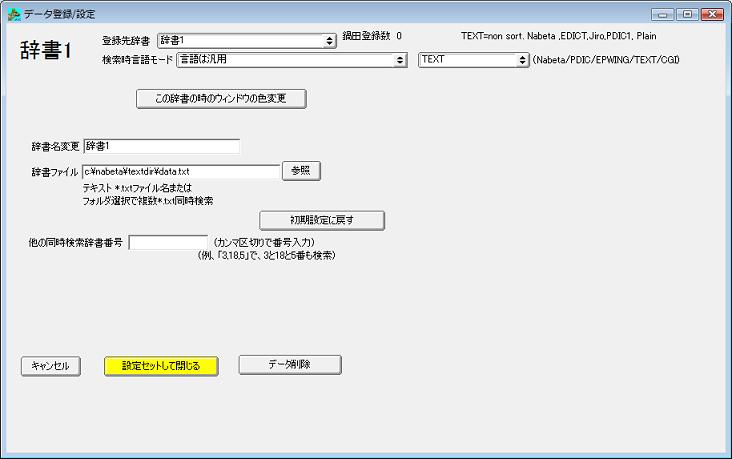
鍋田テキスト、辞郎テキスト、PDIC1行テキスト、EDICTテキスト(CEDICTとWadoku含む。Windows版 Ver 4.8から対応)と、プレインテキストを変換せずにそのまま検索できます。
文字コードはSJIS、EUC、UTF-8、UCS2を自動認識して検索します。 同じフォルダにテキストファイルを入れておけば文字コードが違う複数のファイルを同時検索もできます。
Ver 5.0以降の辞郎テキストのみSJIS順でソートされている必要があります。
それ以外はソートされている必要はありません。
テキストファイルの直接検索では高速検索機能が働かないので鍋田形式に変換したほうが良い場合があります。
鍋田形式バイナリを経由して鍋田CGIデータに変換させることも可能で、こちらも高速検索ができます。
巨大テキストでは検索速度が遅くなります。
テキスト形式は自動判別します。プレインテキスト(書式なしの普通のテキスト)の場合はVer 4.8未満はバグがあります。
(Ver 4.8は2011年11月21現在、まだ公開していませんが完成して公開準備中です。) 拡張子*.txtのテキストファイルを検索する設定をする場合は、右上の「Nabeta/PDIC/EPWING/TEXT/CGI」で「TEXT」を選んでください。
「辞書ファイル」を入力して「設定セットして閉じる」ボタンを押すと完了です。
フォルダを指定した場合は、フォルダ内の拡張子*.txtのファイルを全て同時検索します。
拡張子*.txtのファイル名を指定した場合はそのファイルのみ検索します。
テキストファイル以外との辞書と同時検索する場合は、「他の同時検索辞書番号」の入力欄に他の辞書番号を半角でカンマ区切りで書き「辞書グループ(串刺し)(他の同時検索辞書)セット」ボタンをクリックします。 。
例えば、「3,18,5」の入力で3と18と5の辞書番号の辞書を順に検索します。
テキストファイル設定画面では「登録元ファイルを指定して登録開始」ボタンは消えます。これはクリックする必要はありません。
テキストファイルの直接検索は、登録変換時間がかからない、データサイズが小さい、複数辞書の同時検索が簡単、ひとつの辞書のファイルがひとつで管理しやすいなどの利点があります。
欠点は、高速検索機能は働かず、検索時間が遅い場合があることです。
データ編集や、単語の追加は、別途テキストエディタを用意し、テキストエディタで行えます。
高速検索する場合は鍋田バイナリ形式に変換することで可能です。
鍋田バイナリ形式を経由し鍋田CGIデータを作成することで可能でこちらも高速検索ができます。
プレインテキストは変換できません。
鍋田形式バイナリに変換可能なテキストファイルは、鍋田テキスト、CSVファイル、EDICTテキスト(CEDICTとWadoku含む)、辞郎テキスト、PEJVO.TXT形式テキスト、Wx2+テキストPDIC1行テキスト、PDICテキストです。
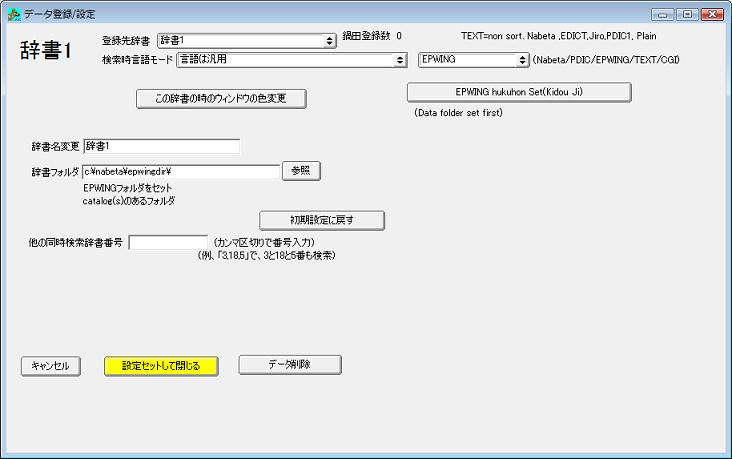
EPWINGまたは電子ブック(EB)を検索する設定をする場合は、右上の「Nabeta/PDIC/EPWING/TEXT/CGI」で「EPWING」を選んでください。
「辞書フォルダ」を入力します。
EPWINGのCATALOGまたはCATALOGSがあるフォルダを指定してください。
起動時の副本を設定したい場合は、データフォルダセットの後に、「EPWING fukuhon Set(Kidou Ji)」ボタンを押して選びます。
副本とは、ひとつのCD-ROMに複数の辞書があるデータのEPWINGデータの、ひとつひとつの辞書のことです。
例えば、英和辞典と国語辞典があるEPWINGデータで、起動時に英和辞典を検索できるようにするか国語辞典を検索できるようにするかを設定します。
最後に「設定セットして閉じる」ボタンを押すと完了です。
複数のファイルがある場合は辞書番号を変えて、別の辞書にファイル名を設定してください。
複数の辞書を同時検索する場合は、「他の同時検索辞書番号」の入力欄に他の辞書番号を半角でカンマ区切りで書き「辞書グループ(串刺し)(他の同時検索辞書)セット」ボタンをクリックします。 。
例えば、「3,18,5」の入力で3と18と5の辞書番号の辞書を順に検索します。
EPWING設定画面では「登録元ファイルを指定して登録開始」ボタンは消えます。これはクリックする必要はありません。
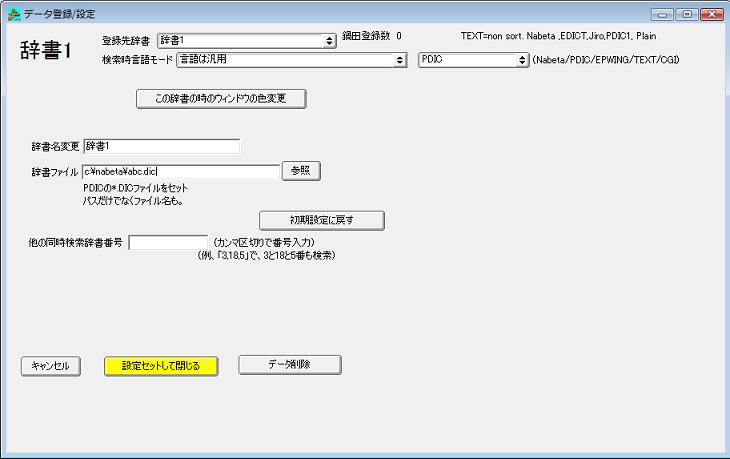
PDICの拡張子*.DICのファイルを直接検索する場合の説明です。
PDIC1行テキストやPDICテキスト(単語と訳語が一行ずつ交互のテキスト)などの各種テキストの場合は、鍋田バイナリ形式に変換してください。
また、拡張子*.DICのPDICデータを鍋田辞書を使って各種テキストファイルに変換したい場合は、以下の説明でまずPDICデータを直接検索できるようにしてください。
PDICの拡張子DICのファイルを検索する設定をする場合は、右上の「Nabeta/PDIC/EPWING/TEXT/CGI」で「PDIC」を選んでください。
「辞書ファイル」を入力して「設定セットして閉じる」ボタンを押すと完了です。
このとき、フォルダではなく、パスを含めた*.DICのファイルを指定してください。
複数のファイルがある場合は辞書番号を変えて、別の辞書にファイル名を設定してください。
複数の辞書を同時検索する場合は、「他の同時検索辞書番号」の入力欄に他の辞書番号を半角でカンマ区切りで書き「辞書グループ(串刺し)(他の同時検索辞書)セット」ボタンをクリックします。 。
例えば、「3,18,5」の入力で3と18と5の辞書番号の辞書を順に検索します。
PDIC設定画面では「登録元ファイルを指定して登録開始」ボタンは消えます。これはクリックする必要はありません。
鍋田辞書でPDICを直接検索する場合は読み込み専用でデータ編集、追加は鍋田辞書単体ではできません。(PDICを使えばできます。)
PDIC/Unicodeでは一部、対応していないデータがあります。
PDICの*.DICデータは、PDIC1行テキストなどのテキスト経由で、鍋田バイナリ形式に変換することも可能です。
PDICの*.DICデータからPDIC1行テキストや鍋田テキストへの変換は、鍋田辞書でもでき発音記号部も取り出せます。(PDIC/Unicodeでは一部対応していないデータがあります。
PDICでもPDIC1行テキストの出力はできると思いますが発音記号部が出力されないかも知れません。(最近のバージョンでどうなっているかは調べていません。)
鍋田CGIデータは、ファイルがひとつで、ファイルサイズも割と小さめで(テキストファイルよりも大きいですが)変換登録無しで高速検索できるのでデータの配布形式に向いています。
また、Perl版またはPHP版の鍋田辞書を使ってオンラインの検索WEBサイトを構築したい場合は鍋田CGIデータに変換する必要があります。
変換元は、鍋田バイナリのみになります。
元ファイルがテキストファイルなどの場合は、まず鍋田バイナリ形式に変換します。
メニューの「データ」の「鍋田辞書CGI用データ出力」でCGIデータが作成できます。
作成時間はあまりかかりません。
ヘルプ
鍋田辞書ホームページ